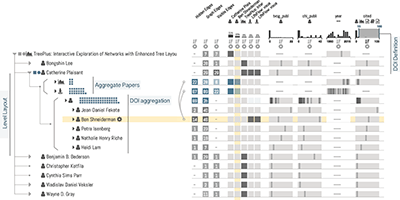
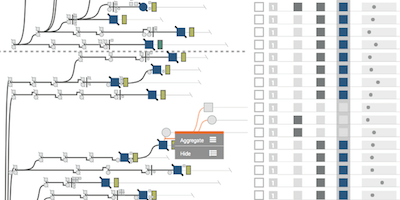
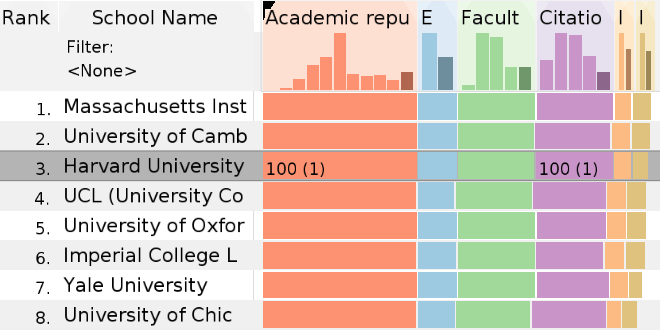
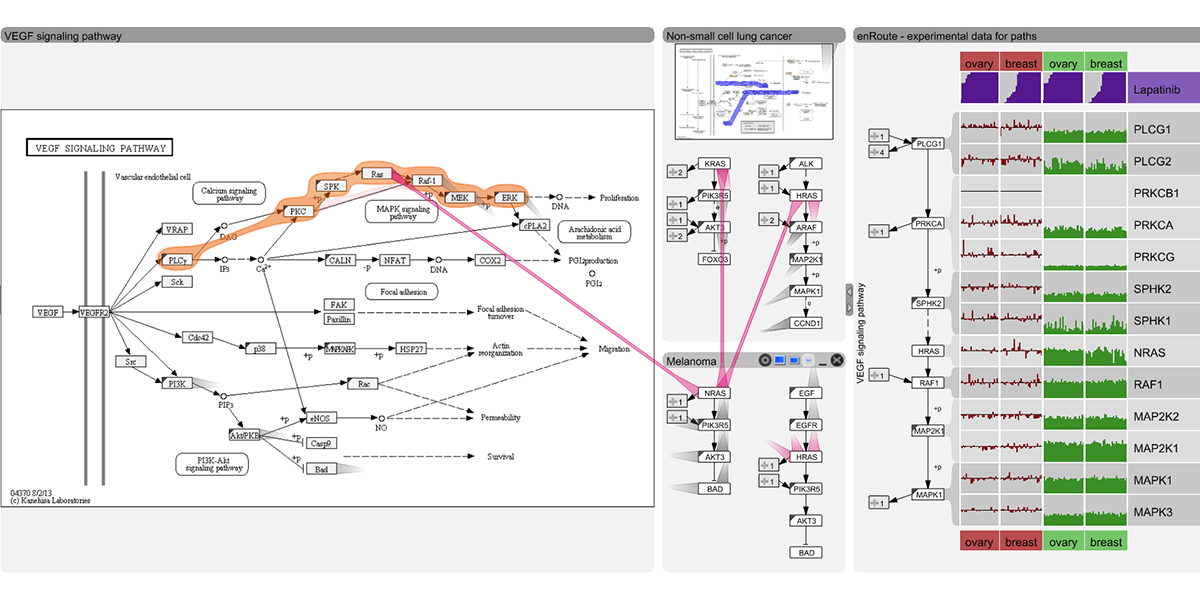
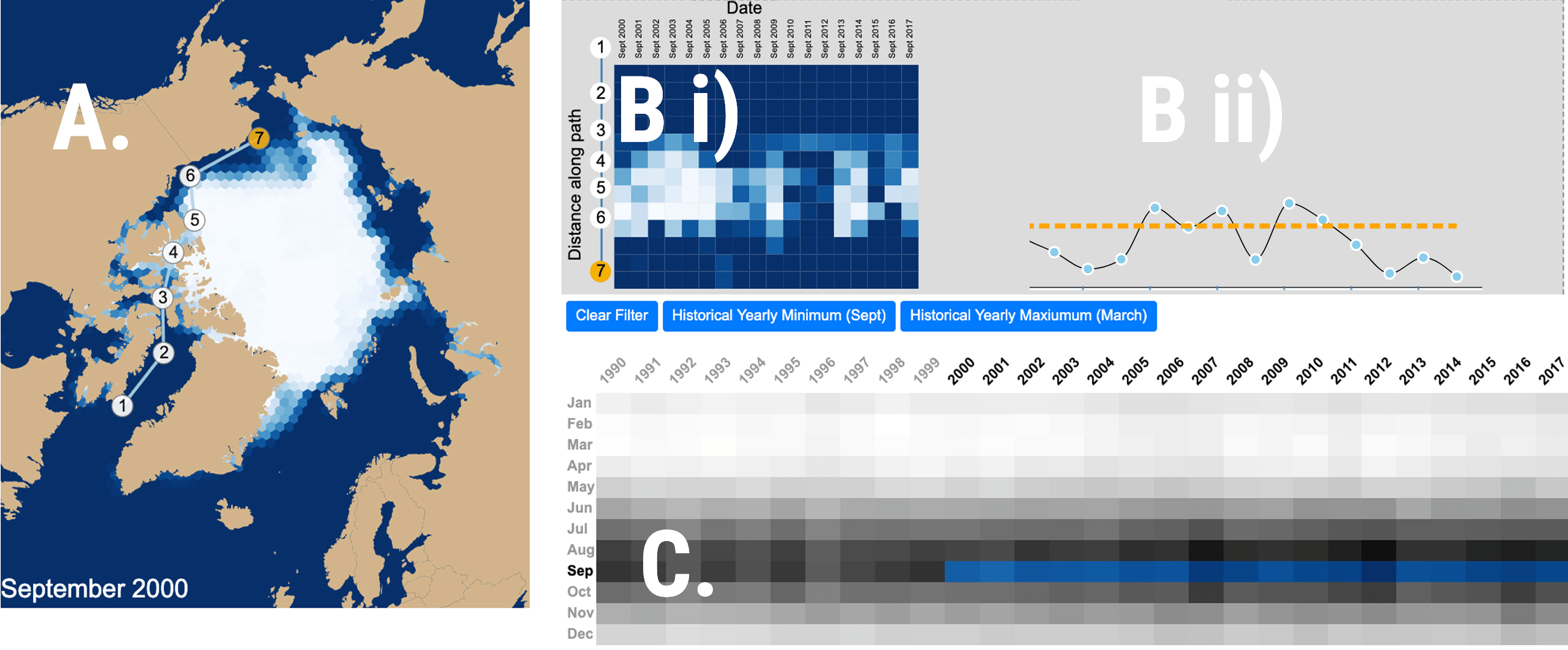
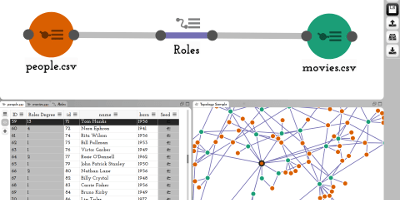
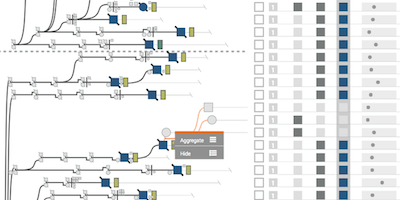
My research is on data visualization and human computer interaction. I design, build, and study interactive visual data analysis solutions to aid researchers in data driven fields, such as biology and medicine, in understanding and communicating complex data sets. I also investigate how to make visualization reproducible, how to integrate visualizations with computational workflows, and how to make data visualizations accessible to blind and low-vision users. Finally, I also develop infrastructure for crowd-sourced user studies.
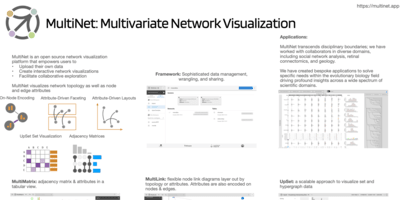
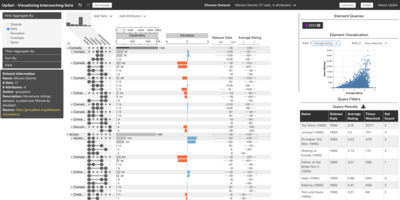
I am the recipient of an NSF CAREER award and multiple best paper awards or honorable mentions at IEEE VIS, ACM CHI, and other conferences, as well as a test of time award at IEEE VIS. I also received a best dissertation award from my alma mater. I co-founded Datavisyn, a startup company developing visualization solutions for the pharmaceutical industry. I am an associate editor for IEEE TVCG and IEEE CG&A, and I served as area papers chair for IEEE VIS in 2021 and 2023. In addition to writing papers, our lab publishes a lot of visualization software. My most popular tool is UpSet, a set visualization technique. Other tools include reVISit, a platform for designing online user studies, MultiNet, a network visualization platform and trrack, a library for tracking provenance in interactive applications. You can find other software on our GitHub Page.
Before joining Graz University of Technology, I was a Professor at the University of Utah. Prior to that, I was a lecturer and post-doctoral visualization researcher at Harvard University. I received my PhD, master’s, and undergraduate degrees from Graz University of Technology.
Provenance as a Bridge Between Data Analysis ModalitiesKey |
PDF
Abstract: In visualization, provenance is widely used for action recovery, to document analysis processes, and to analyze user behavior. In this talk, however, I will focus on an exciting application of provenance: to bridge between code-based and interactive and visual data analysis. Code-based and interactive data analysis have different strengths and weaknesses. Some operations can be more easily executed in one than in the other. Interactive visualization tends to be more "natural" and easier to understand, but code-based analysis is typically more reproducible. While traditionally these two approaches can't be easily combined, I'll show how we can leverage provenance data to tackle these issues and design a truly integrated analysis environment.
Visualization in Data Science: Challenges and OpportunitiesKey |
PDF
Abstract: In visualization, provenance is widely used for action recovery, to document analysis processes, and to analyze user behavior. In this talk, however, I will focus on an exciting application of provenance: to bridge between code-based and interactive and visual data analysis. Code-based and interactive data analysis have different strengths and weaknesses. Some operations can be more easily executed in one than in the other. Interactive visualization tends to be more "natural" and easier to understand, but code-based analysis is typically more reproducible. While traditionally these two approaches can't be easily combined, I'll show how we can leverage provenance data to tackle these issues and design a truly integrated analysis environment.
Celebrating 30 Years of ICG, Graz University of Technology, Graz, Austria, 2023-06-12
Spatial Omics Visualizations: Lessons Learned from Networks and MapsKey |
PDF
Abstract: Spatial omics analysis poses great challenges for data visualization as large data vectors are collected on dense, spatially located biological entities. However, there are parallels to other data types where location or topology are imperative: maps and networks. I will give an overview of the challenges encountered when analyzing spatial omics data, and highlight parallels and differences to maps and networks. I will then speculate on how visualization techniques for maps and networks could be leveraged for spatial omics data.
BioVis@VIS, IEEE VIS, New Orleans, USA (virtual), 2021-10-25.
Opportunities for Understanding Semantics of User InteractionsKey |
PDF
Abstract: Most logging approaches record system events at a fairly low level of abstraction. In this talk, I will argue that higher levels of abstraction are possible and desirable. I will highlight opportunities for increasing semantics that software developers have by carefully recording meaningful events. I will then show that we can leverage algorithmic methods to infer user-intents. Finally, I will show opportunities for eliciting key information from insights directly from users. Explicitly asking users about their intentions has benefits for users, as they can later retrace their steps more efficiently, and system developers, as they can learn more about usage patterns of their system and motivations of their users. There are diverse user input modalities that can provide information at different levels of abstraction and invasiveness. These modalities range from multiple choice responses, to structured notes, to “think-aloud-like” approaches. In combination, these approaches are promising for building systems that have a better understanding of their users and hence can support users in their analytical tasks.
What is Data Visualization and Why Do We Care About it for Biomedical Applications?Key |
PDF
May Institute, Computation and statistics for mass spectrometry and proteomics, Northeastern University, Boston, MA, USA, 2019-05-06.
Invited Talks
Interactive Visualization in Biological Data Science: From Bespoke Tools to Reusable LibrariesKey |
PDF
Abstract: Interactive data visualization is central to modern data science, particularly within the life sciences. It enables researchers to directly engage with their data, quickly explore hypotheses, and uncover patterns with minimal friction. Visualization solutions range from highly specialized tools designed for specific biological challenges to flexible, general-purpose libraries used across domains.
In this talk, I will present two examples at opposite ends of this spectrum. The first is a bespoke, domain-specific visualization system developed to address the complex task of analyzing live-cell microscopy data. The second demonstrates how interactive visualizations can be seamlessly integrated with Python code in Jupyter Notebooks, creating a powerful environment for exploratory analysis. Together, these examples highlight both the current landscape and future potential of visualization in biological data science.
reVISit: A Toolking for Data Visualization ExperimentsKey |
PDF
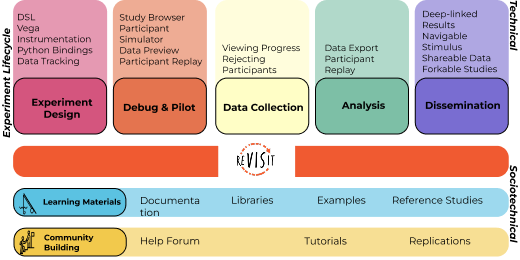
Abstract: In this talk we introduce the reVISit framework for designing and running empirical studies online. Traditional survey tools limit the flexibility and reproducibility of online experiments. To remedy this, we introduce a domain-specific language, the reVISit Spec, that researchers can use to design complex online user studies. reVISit Spec, combined with the relevant stimuli, is compiled into a ready-to-deploy website that handles all aspects of a user study, including sophisticated provenance-based data tracking, randomization, etc. reVISit is a community focused project and ready to use! Visit https://revisit.dev/ to get started.
The reVISit User Study Platform and Applications in Studying MisinformationKey |
PDF
Abstract: In this talk I introduce the reVISit framework for designing and running empirical studies online. Traditional survey tools limit the flexibility and reproducibility of online experiments. To remedy this, we introduce a domain-specific language, the reVISit Spec, that researchers can use to design complex online user studies. reVISit Spec, combined with the relevant stimuli, is compiled into a ready-to-deploy website that handles all aspects of a user study, including sophisticated provenance-based data tracking, randomization, etc. reVISit is a community focused project and ready to use! Visit https://revisit.dev/ to get started.
I will then pivot to talk about data-driven misinformation in the form of charts shared on social networks. I will demonstrate that “lying with charts” doesn’t work the way we (used to) think about it, and introduce a few strategies to “protect” charts and charting tools from being abused by malicious users. I will connect back to reVISit by illustrating how we leveraged it to run a series of crowd-sourced experiments.
A Hodgepodge of Visualization Research: Provenance, User Studies, MisinformationKey |
PDF
Abstract: In this talk I want to introduce three not particularly related research topics: provenance, user studies, and visualization-based misinformation.
In visualization, provenance is widely used for action recovery, to document analysis processes, and to analyze user behavior. I will focus on an exciting new application of provenance: to bridge between code-based and interactive, visual data analysis. While traditionally these two approaches can’t be easily combined, I’ll show how we can leverage provenance data to tackle these issues and design a truly integrated analysis environment.
Next, I will introduce the reVISit framework for designing and running empirical studies online. Traditional survey tools limit the flexibility and reproducibility of online experiments. To remedy this, we introduce a domain-specific language, the reVISit Spec, that researchers can use to design complex online user studies. reVISit Spec, combined with the relevant stimuli, is compiled into a ready-to-deploy website that handles all aspects of a user study, including sophisticated provenance-based data tracking, randomization, etc. reVISit is a community focused project and ready to use! Visit https://revisit.dev/ to get started.
Finally, I will talk about data-driven misinformation in the form of charts shared on social networks. I will demonstrate that “lying with charts” doesn’t work the way we (used to) think about it, and introduce a few strategies to “protect” charts and charting tools from being abused by malicious users.
I will conclude by discussing how these topics mesh together after all, as (a) each project benefits from developments in the others, and (b) they all are enabled by my approach of combining engineering with visualization research.
Visualization in Oncological Data Science Now and in the Future: From Cancer Cell Microscopy to Reproducible Visual AnalysisKey |
PDF
Oncological Data Science Symposium, ODSi, Huntsman Cancer Institute, Utah, 2023-02-28
Empirical Evaluation of Complex Interactive Visualization TechniquesVideo |
Key |
PDF
Abstract: Traditional empirical user studies tend to focus on testing aspects of visualizations or perceptual effects that can be fully controlled. Evaluating or comparing complex interactive visualization techniques, in contrast, is much more difficult, as complexity increases confounders. This challenge is aggravated when using crowdsourcing for evaluation, as crowd participants tend to be novices with limited motivation for excelling at a task. In this talk I will introduce methods to run and analyze such studies for complex visualization techniques, including procedural suggestions for crowdsourced studies, design of stimuli for testing, instrumentation of stimuli, and analysis of user behavior based on the data collected.
SCI VIS Seminar, University of Utah, USA, 2022-08-31.
Institute for Computer Graphics, TU Wien, Vienna, Austria, 2022-06-03.
Literate Visualization: Making Visual Analysis Sessions Reproducible and ReusableVideo |
Key |
PDF
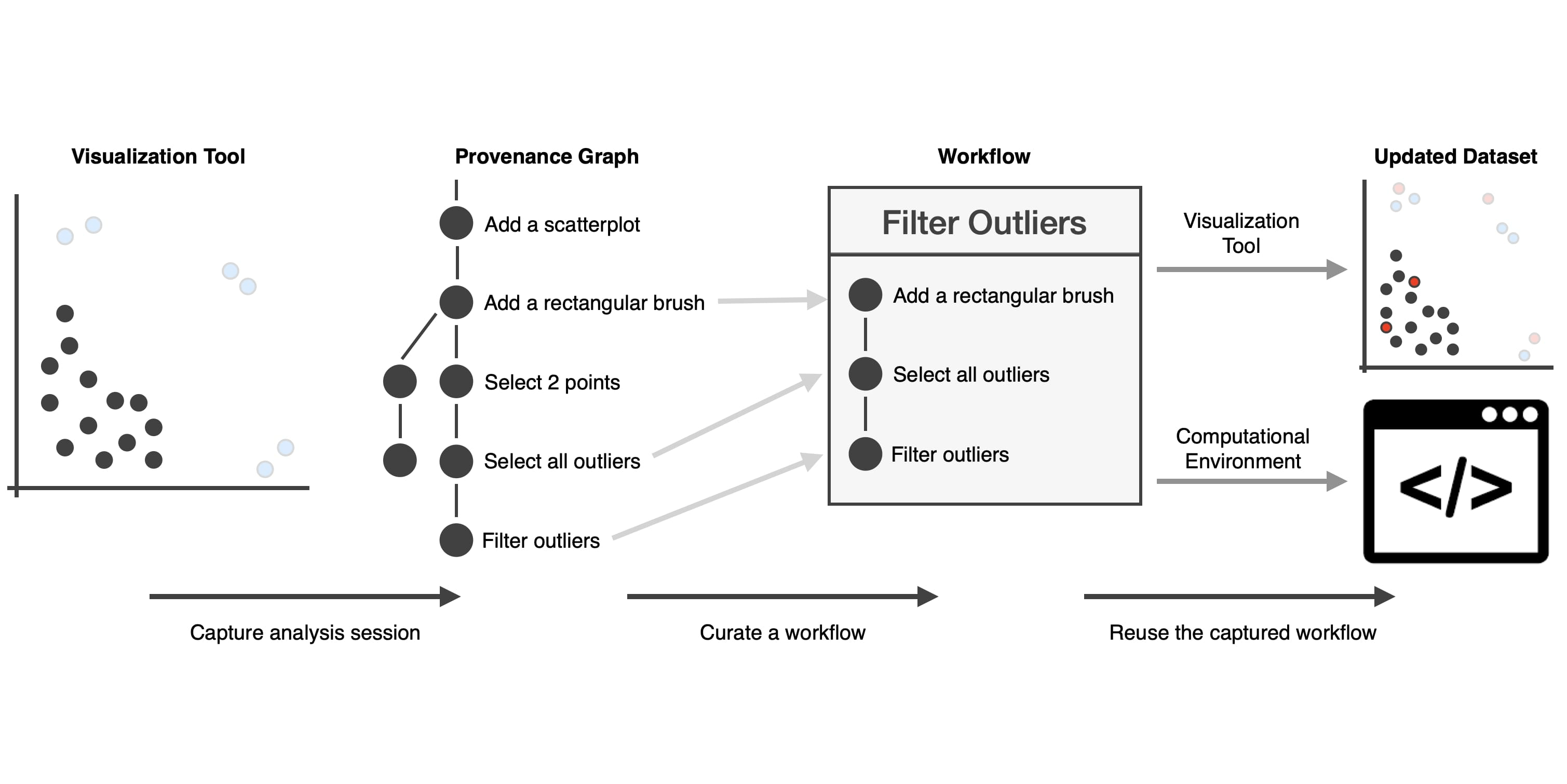
Abstract: Interactive visualization is an important part of the data science process. It enables analysts to directly interact with the data, exploring it with minimal effort. Unlike code, however, an interactive visualization session is ephemeral and can't be easily shared, revisited, or reused. Computational notebooks, such as Jupyter Notebooks, R Markdown, or Observable are widely used in data science. These notebooks are an embodiment of Knuth's “Literate Programming”, where the logic of a program is explained in natural language, figures, and equations. As a consequence, they are both reproducible, and reusable. In this talk, I will sketch approaches to “Literate Visualization”. I will show how we can leverage provenance data of an analysis session to create well-documented and annotated visualization stories that enable reproducibility and sharing. I will also introduce work on inferring analysis goals, which allows us to understand the analysis process at a higher level. Understanding analysis goals enables us to enhance interaction capabilities and even re-used visual analysis processes. I will conclude by demonstrating how this provenance data can be leveraged to bridge between computational and interactive environments.
Visualization Summer School of Zhejiang University, China (virtual), 2022-07-07.
VRVis Zentrum für Virtual Reality und Visualisierung, Vienna, Austria, 2022-03-24.
Graz University of Technology, Graz, Austria, 2021-11-11.
Séminaire LIRIS, CNRS / INSA Lyon / Université Lyon 1 & 2 / École Centrale de Lyon, Lyon, France, 2021-10-18.
Datavisyn Public Lecture Series, datavisyn, Linz, Austria, 2021-07-02.
ICG Lab Talk, Johannes Kepler University, Linz, Austria, 2021-06-15.
Departmental Seminar, Department of Computer Science, City University London, London, UK (virtual), 2020-11-17.
Goldman Sachs Tech Expo, Salt Lake City, UT, USA, 2020-07-24.
Utah Center for Data Science Seminar, Salt Lake City, UT, USA, 2020-01-06.
Spatial Omics Visualizations: Lessons Learned from Networks and MapsKey |
PDF
Abstract: Spatial omics analysis poses great challenges for data visualization as large data vectors are collected on dense, spatially located biological entities. However, there are parallels to other data types where location or topology are imperative: maps and networks. I will give an overview of the challenges encountered when analyzing spatial omics data, and highlight parallels and differences to maps and networks. I will then speculate on how visualization techniques for maps and networks could be leveraged for spatial omics data.
Worcester Polytechnic Institute, BCB Seminar Series, 2021-12-09.
Driving Scientific Discovery with Interactive Visual Data AnalysisKey |
PDF
Abstract: Today, scientific discovery is increasingly data-driven and enabled by computational tools. However, there are many aspects of the data science process for which purely automatic approaches do not suffice. In a typical data analysis scenario, reasoning and incorporating contextual knowledge is essential, and when decisions are ultimately made by humans, they need to be knowledgeable about the data and the methods applied. In my talk I will show how to enable this interplay between data, computation, visualization, and humans to augment intelligence. My work usually falls into one of three categories (I) technical contributions, (II) domain-driven techniques, and (III) empirical/theoretical work.
As an example for a technical contribution, I will introduce my vision for “Literate Visualization”, an analogy to Knuth’s “Literate Programming”, which is widely used in the form of computational notebooks in data science today. We can leverage provenance data of an analysis session to create well-documented and annotated visualization stories that enable reproducibility and sharing. By semi-automatically inferring analyst's intents for operations such as brushing, aggregating, filtering, etc., we can improve reproducibility and enable reusability, which in turn also allows us to seamlessly bridge between interactive workflows and computational workflows.
To showcase my domain-driven work, I will describe a technique we developed to analyze large clinical genealogies with the purpose of identifying suicide cases that have a likely genetic component.
Department of Computer Science, University of Copenhagen, Denmark, 2021-10-04
Institute for Science and Technology (IST) Austria, Klosterneuburg, Austria, 2020-02-25.
A Framework for Creative Visualization-Opportunities WorkshopsPDF
NIH-NCI Workshop on Accelerating Cancer Research through User-Centered Software Design, Washington, DC, USA, 2019-01-07.
Enabling Scientific Discovery through Interactive Visual Data AnalysisKey |
PDF
Adobe, Lehi, UT, USA, 2019-04-10.
Lucid Software, Salt Lake City, UT, USA, 2019-03-12.
Goldman Sachs Tech Expo, Salt Lake City, UT, USA, 2017-06-28.
Department Of Biomedical Informatics, University of Utah, Salt Lake City, UT, USA, 2017-04-06.
Walmart, Tech Tuesday, Bentonville, AK, USA, 2017-02-07.
Marth Lab, Department of Human Genetics, University of Utah, Salt Lake City, UT, USA, 2016-08-25.
Pacific Northwest National Laboratory, Richland, WA, USA, 2016-07-01.
Huntsman Cancer Institute, Salt Lake City, UT, USA, 2016-03-30.
Camp Lab, Huntsman Cancer Institute, University of Utah, Salt Lake City, UT, USA, 2015-11-23.
Layout Adaption Strategies for Visualizing Multivariate NetworksKey |
PDF
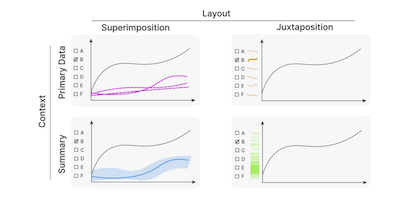
Abstract: When visualizing multivariate networks we commonly have to make trade-offs between optimizing for the readability of a network's topology and the attributes associated with its nodes and or edges. In this talk I will first introduce the design space of multivariate network visualization, and then go into details about one strategy: layout adaption. I will give examples that demonstrate that different layout adaption strategies occupy a sweet-spot on the continuum between layouts optimized for attributes and topology. I will show examples for general purpose networks, such as co-author networks and for special graph types such as tree-like genealogies.
University of Calgary, Calgary, AB, Canada, 2018-06-18.
Lineage: Visualizing Multivariate Clinical Data in Genealogy GraphsKey |
PDF
Abstract: The majority of diseases that are a significant challenge for public and individual heath are caused by a combination of hereditary and environmental factors. The Utah Population Database is a unique resource to study these multifactorial diseases. Incorporating familial relationships between cases with other data can provide insights into shared genomic variants and shared environmental exposures that may be implicated in such diseases. The analysis of this data, however, is challenging. In this talk, we will introduce Lineage, a novel visual analysis tool designed to support domain experts who study psychiatric multifactorial diseases with UPDB data.
NIH-NCI Workshop on Accelerating Cancer Research through User-Centered Software Design, Washington, DC, USA, 2019-01-07.
Genome Rounds, University of Utah, SLC, UT, USA, 2018-08-24.
Department of Psychiatry, University of Utah, SLC, UT, USA, 2018-06-05.
BioIT World Conference & Expo, Boston, MA, USA, 2018-05-17.
Harvard John A. Paulson School of Engineering and Applied Sciences, Harvard University, Cambridge, MA, USA, 2018-05-16.
Visualizing Biological Data: Pathway Graphs, Genealogies, and Alternative SplicingKey |
PDF
Helmholtz Diabetes Center, Munich, Germany, 2018-10-29.
Translational Genomics Research Institute (TGen), Phoenix, AZ, USA, 2018-08-14.
Association for Molecular Pathology (AMP) Annual Meeting, Salt Lake City, UT, USA, 2017-11-17.
Merck Research Laboratories, Boston, MA, USA, 2017-06-15.
Department Of Biomedical Informatics, Harvard Medical School, Boston, MA, USA, 2017-06-14.
Enabling Scientific Discovery through Interactive Visual Data AnalysisPPT |
PDF
University of Vienna, Vienna, Austria, 2015-08-07.
Adobe Research, San Francisco, CA, USA, 2015-04-06.
EPFL, Lausanne, Switzerland, 2015-03-26.
University of Utah, Salt Lake City, UT, USA, 2014-12-03.
University of St. Andrews, St. Andrews, Scotland, 2014-11-03.
UpSet: Visualization of Intersecting SetsPPT |
PDF
Data Ventures, Harvard University, Cambridge, MA, USA, 2015-04-23.
BioIT World Conference & Expo, Boston, MA, USA, 2015-04-22.
Tufts University, Sommerville, MA, USA, 2014-10-29.
Visual Data Analysis for Biology and PharmacologyPPT |
PDF
PerkinElmer, Boston, MA, USA, 2014-11-05.
Novartis Institutes for BioMedical Research, Cambridge, MA, USA, 2014-07-09.
Visualizing Relationships between Biological PathwaysPPT |
PDF
Drug Discovery on Target Conference, Boston, MA, USA, 2014-10-08.
BioIT World Conference & Expo, Boston, MA, USA, 2014-05-01.
DBMI, Harvard Medical School, Boston, MA, USA, 2014-04-17.
Visualization Approaches for Biomolecular DataPPT |
PDF
Georgia Tech, School of Interactive Computing, Atlanta, GA, USA, 2014-04-08.
University of Calgary, Department of Computer Science, Calgary, AB, Canada, 2014-02-13.
MIT CSAIL, Cambridge, MA, USA. 2013-04-12.
UMass Lowell, Lowell, MA, USA, 2013-11-06.
Visualizing Multi-Attribute Rankings & A Very Short Visualization IntroductionPPT |
PDF
Harvard Graduate School of Education, Strategic Data Project, Cambridge, MA, USA, 2014-03-07.
Novartis Institutes for BioMedical Research, Cambridge, MA, USA, 2013-07-29.
enRoute: Dynamic Path Extraction from Biological Pathway Maps for Exploring Heterogeneous Experimental DatasetsPPT |
PDF
BioIT World Conference & Expo, Boston, MA, USA, 2013-04-10.
Visualizing Biological Data (VIZBI) 2013, Cambridge, MA, USA, 2013-03-20.
Symposium on Understanding Cancer Genomics through Information Visualization at Tokyo University, Tokyo, Japan, 2013-02-22.
Visualizing Biomolecular Data with the Caleydo FrameworkPDF
CBMI, Harvard Medical School, Boston, MA, USA, 2011-08-12.
MRC Laboratory of Molecular Biology (LMB), Cambridge, UK, 2010-09-21.
European BioInformatics Institute (EBI), Cambridge, UK, 2010-09-20.
Caleydo: Visual Analysis of Biomolecular Data
VCBM 2010 Leipzig, Germany, 2010-07-02.
Caleydo and Visual Links
VRVis Research Company, Vienna, Austria. 2010-03-11.
Caleydo: Visualization of Gene Expression Data in the Context of Biological Processes
AUVA Research Center for Traumatology, Vienna, Austria, 2009-02-26.
Novel InfoVis Techniques Applied to Pathways and Gene Expression Data
Institute for Genomics and Bioinformatics, Graz University of Technology, Austria, 2008-07-10.
Paper Presentations
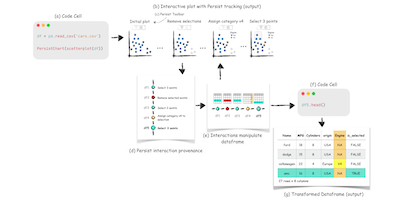
Persist: Persistent and Reusable Interactions in Computational NotebooksKey |
PDF
Abstract: In visualization, provenance is widely used for action recovery, to document analysis processes, and to analyze user behavior. In this talk, however, I will focus on an exciting application of provenance: to bridge between code-based and interactive and visual data analysis. Code-based and interactive data analysis have different strengths and weaknesses. Some operations can be more easily executed in one than in the other. Interactive visualization tends to be more "natural" and easier to understand, but code-based analysis is typically more reproducible. While traditionally these two approaches can't be easily combined, I'll show how we can leverage provenance data to tackle these issues and design a truly integrated analysis environment.
Zach Cutler
| Visualization tools, Provenance, Storytelling
Khandaker Abrar Nadib
| Human Centered Computing, Visualization, Applied Data Science
Graduated PhD Students
Maxim Lisnic, PhD '25 Devin Lange
| Cell Microscopy Visualization, Cancer Cell Visualization, Identifying Falsification in Scientific Data
Kiran Gadhave, PhD '24 Haihan Lin, PhD '23, Now at Lucid Software Jen Rogers, PhD '22, Now PostDoc at Tufts University Carolina Nobre, PhD '20, Now Faculty at the University of Toronto
Christian Partl, PhD '18 (co-advised with Dieter Schmalstieg)
Former Students
Zoe Exelbert, BS '25 Luke Schreiber
| Data Visualization, Health Science
Ishrat Jahan Eliza Sunny Siu, BS/MS '21 Shaurya Sahai, MS '21 Zach Cutler
| Visualization tools, Provenance, Storytelling
Pranav Rajan, B.S.'21 Hannah Bruns, BS '20 Max Marno, PhD rotation '20
Ilkin Safarli
Sai Varun, MS '20 Dylan Wootton, BS '19, Now PhD student at MIT Shuvrajit Mukherjee T Cameron Waller Pranav Dommata, MS '18 Sahar Mehrpour, PhD rotation '17
Mengjiao Han, PhD rotation '17
Asmaa Aljuhani, PhD rotation '17 Annie Cherkaev, PhD rotation '17 Sunny Hardasani, MS '16
Anirudh Narasimhamurthy, MS '16 Michael Kern, MS '16 Murali Krishna Teja Kilari, MS '17
Sateesh Tata, MS '16
Roy Bastien, BS '16
Priyanka Parekh, BS '16
Shreya Singh, MS '15
Varsha Alangar, MS '15
Rasvan Iliescu, MS '14
Alain Ibrahim, MS '14
Tamar Rucham, MS '14
Gabriel Hase, MS '14
Conor Myhrvold, MS '14
Ran Sofia Hou, BS '13 (co-advised with Joe Blitzstein)
Thomas Geymayer, MS '12, BS '11 (with D. Schmalstieg)
Christian Partl, MS '12 (with D. Schmalstieg)
Michael Lafer, BS '10 (with D. Schmalstieg)
Hannes Plank, BS '11 (with D. Schmalstieg)
Jürgen Pillhofer, MS '10 (with D. Schmalstieg)
Michael Wittmayer, BS '09 (with D. Schmalstieg)
Helmut Pichlhöfer, BS '10 (with D. Schmalstieg)
Oliver Pimas, BS '10 (with D. Schmalstieg)
Bernhard Schlegl, MS '09 (with D. Schmalstieg)
Werner Puff, MS '10 (with D. Schmalstieg)
Christian Partl, BS '09 (with D. Schmalstieg)
Stefan Sauer, BS '09 (with D. Schmalstieg)
Human Centered Data Analysis | CS 6957
Spring 2023
Visualization for Data Science | CS 5630 / CS 6630
Fall 2022, Fall 2020, Fall 2019, Fall 2018, Fall 2017, Fall 2016, Fall 2015 http://dataviscourse.net
Introduction to Data Science | COMP 5360 / MATH 4100
Spring 2018, Spring 2019, Spring 2020, Spring 2021 http://datasciencecourse.net
Co-Instructor: Braxton Osting
Introduction to Data Science | CS 5963 / MATH 3900
Fall 2016 http://datasciencecourse.net
Co-Instructor: Braxton Osting
Visualization Seminar | CS 7942
Spring 2018, Fall 2017, Spring 2017, Fall 2016